
Dreamstime_suwinpuengsamrong_139968432




Recommended
Recommended
Members Only Content
William Wong | Electronic Design



Members Only Content

SEARCH FOR DATA SHEETS, PRICE, STOCK, AND PART STATUS OF ELECTRONIC COMPONENTS
SEARCH FOR DATA SHEETS, PRICE, STOCK, AND PART STATUS OF ELECTRONIC COMPONENTS
Learning Resources
Learning Resources




Sponsored Content

Sponsored Content
Industry Insights
Industry Insights
311250589 © Anatolii Savitskii | Dreamstime.com

Keysight and Dreamstime_lescunliffe_23231826





Dreamstime_kiosk88generated_by_ai_11195757


Dreamstime_ronstik_111023808


Stanford University and Amazon

Andrei Dzemidzenka, Dreamstime

Best Electric Machine/YouTube

Raspberry Pi Foundation

Dreamstime_alekseigorodenkov_30

1025574 © Dana Rothstein | Dreamstime.com

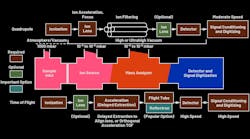

114496245 © Kawee Wateesatogkij | Dreamstime.com

260215519 © Scharfsinn86 | Dreamstime.com

Dreamstime_junichishimazaki_1019796241
Embedded World






Dreamstime_susan_sheldon

Dreamstime_dzmitryryzhykau_115899450

Muhammad Shoaib, Dreamstime


dreamstime_137795268_thekaikoro

Kittipong_jirasukhanont_dreamstime_11467


Dreamstime_ekkalucksangkla_1082822391

Premio and Dreamstime_shengzhang_1004472341

307008091 © Sorinradulesku2 | Dreamstime.com

Dreamstime_atmosphere1_145936514

Dreamstime_artinun_prekmoung_146913868



Electra Aerospace and Textron Aviation

Surasak Petchang, Dreamstime

Cabe Atwell/Electronic Design

309588159 © Alexei Onufriiciuc | Dreamstime.com

270402045 | Data © imaginariumphoto | Dreamstime.com

48142071 © Kyrylo Glivin | Dreamstime.com

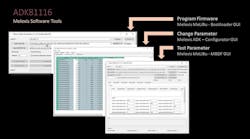
Electronic Design

Dreamstime_luchschen_26003212

Dreamstime_forfunlife_17805192
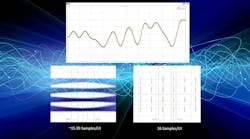
RIGOL Technologies

Dreamstime_marekuliasz_267841133
